 SV Blog SystemVerilog Blog
SV Blog SystemVerilog Blog
Related Articles

The first approach I attempted was a completely parallel approach as shown in the diagram below:
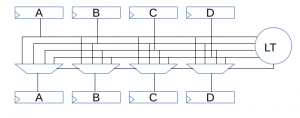
The advantage to this approach, if it meets timing, is that it will produce a result every clock cycle, it’s compact, easy to understand, and uses a reasonable amount of logic.
compare.sv
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 | module compare # ( parameter DWIDTH = 8 ) ( input clk, input [DWIDTH-1:0] a_in, input [DWIDTH-1:0] b_in, input [DWIDTH-1:0] c_in, input [DWIDTH-1:0] d_in, output logic [DWIDTH-1:0] a_out, output logic [DWIDTH-1:0] b_out, output logic [DWIDTH-1:0] c_out, output logic [DWIDTH-1:0] d_out ); logic [DWIDTH-1:0] a_reg; logic [DWIDTH-1:0] b_reg; logic [DWIDTH-1:0] c_reg; logic [DWIDTH-1:0] d_reg; logic a_lt_b; logic a_lt_c; logic a_lt_d; logic b_lt_c; logic b_lt_d; logic c_lt_d; always_ff @(posedge clk) begin a_reg <= a_in; b_reg <= b_in; c_reg <= c_in; d_reg <= d_in; end assign a_lt_b = a_reg < b_reg; assign a_lt_c = a_reg < c_reg; assign a_lt_d = a_reg < d_reg; assign b_lt_c = b_reg < c_reg; assign b_lt_d = b_reg < d_reg; assign c_lt_d = c_reg < d_reg; always_ff @(posedge clk) begin /* verilator lint_off CASEINCOMPLETE */ unique case ({a_lt_b, a_lt_c, a_lt_d, b_lt_c, b_lt_d, c_lt_d}) // A first 6'b111111: begin a_out <= a_reg; b_out <= b_reg; c_out <= c_reg; d_out <= d_reg; end 6'b111110: begin a_out <= a_reg; b_out <= b_reg; c_out <= d_reg; d_out <= c_reg; end 6'b111011: begin a_out <= a_reg; b_out <= c_reg; c_out <= b_reg; d_out <= d_reg; end 6'b111001: begin a_out <= a_reg; b_out <= c_reg; c_out <= d_reg; d_out <= b_reg; end 6'b111100: begin a_out <= a_reg; b_out <= d_reg; c_out <= b_reg; d_out <= c_reg; end 6'b111000: begin a_out <= a_reg; b_out <= d_reg; c_out <= c_reg; d_out <= b_reg; end // B first 6'b011111: begin a_out <= b_reg; b_out <= a_reg; c_out <= c_reg; d_out <= d_reg; end 6'b011110: begin a_out <= b_reg; b_out <= a_reg; c_out <= d_reg; d_out <= c_reg; end 6'b001111: begin a_out <= b_reg; b_out <= c_reg; c_out <= a_reg; d_out <= d_reg; end 6'b000111: begin a_out <= b_reg; b_out <= c_reg; c_out <= d_reg; d_out <= a_reg; end 6'b010110: begin a_out <= b_reg; b_out <= d_reg; c_out <= a_reg; d_out <= c_reg; end 6'b000110: begin a_out <= b_reg; b_out <= d_reg; c_out <= c_reg; d_out <= a_reg; end // C first 6'b101011: begin a_out <= c_reg; b_out <= a_reg; c_out <= b_reg; d_out <= d_reg; end 6'b101001: begin a_out <= c_reg; b_out <= a_reg; c_out <= d_reg; d_out <= b_reg; end 6'b001011: begin a_out <= c_reg; b_out <= b_reg; c_out <= a_reg; d_out <= d_reg; end 6'b000011: begin a_out <= c_reg; b_out <= b_reg; c_out <= d_reg; d_out <= a_reg; end 6'b100001: begin a_out <= c_reg; b_out <= d_reg; c_out <= a_reg; d_out <= b_reg; end 6'b000001: begin a_out <= c_reg; b_out <= d_reg; c_out <= b_reg; d_out <= a_reg; end // D first 6'b110100: begin a_out <= d_reg; b_out <= a_reg; c_out <= b_reg; d_out <= c_reg; end 6'b110000: begin a_out <= d_reg; b_out <= a_reg; c_out <= c_reg; d_out <= b_reg; end 6'b010100: begin a_out <= d_reg; b_out <= b_reg; c_out <= a_reg; d_out <= c_reg; end 6'b000100: begin a_out <= d_reg; b_out <= b_reg; c_out <= c_reg; d_out <= a_reg; end 6'b100000: begin a_out <= d_reg; b_out <= c_reg; c_out <= a_reg; d_out <= b_reg; end 6'b000000: begin a_out <= d_reg; b_out <= c_reg; c_out <= b_reg; d_out <= a_reg; end endcase // unique case ({a_lt_b, a_lt_c, a_lt_d, b_lt_c, b_lt_d, c_lt_d}) end endmodule |
The real key to the design is to work out the muxing criteria. This was done using pen and paper in my case.
I’m still working through the systemC side of things for the testbench. The testbench is relatively simple. I have parameterized the data width so I can simply loop through all the values on the four inputs. Currently I am verifying by visual inspection that the outputs are properly sorted, however, I will soon be changing to check the sorting. Here is the CPP code. I encourage you to look at the repo for the entire design.
tb.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | #include "tb.h" void tb::source() { for (int i = 0; i < 8; i++) { cout << i << endl; for (int j = 0; j < 8; j++) { for (int k = 0; k < 8; k++) { for (int l = 0; l < 8; l++) { a_in.write(i); b_in.write(j); c_in.write(k); d_in.write(l); wait(); } } } } wait(); wait(); wait(); wait(); sc_stop(); } void tb::sink() { int a, b, c, d; while(1) { a = a_out.read(); b = b_out.read(); c = c_out.read(); d = d_out.read(); wait(); cout << a << "\t" << b << "\t" << c << "\t" << d << endl; } } |
tb.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #include SC_MODULE(tb) { sc_in clk; sc_out a_in; sc_out b_in; sc_out c_in; sc_out d_in; sc_in a_out; sc_in b_out; sc_in c_out; sc_in d_out; void source(); void sink(); SC_CTOR(tb) { SC_CTHREAD(source, clk.pos() ); SC_CTHREAD(sink, clk.pos() ); } }; |
Results for a ZCU102 targeting 500Mhz:
clk > 500Mhz
LUT: 232
FF: 258
fmax 645Mhz
LUT: 232
FF: 256
